Train@LLaVA-v1.5
Train@LLaVA-v1.5
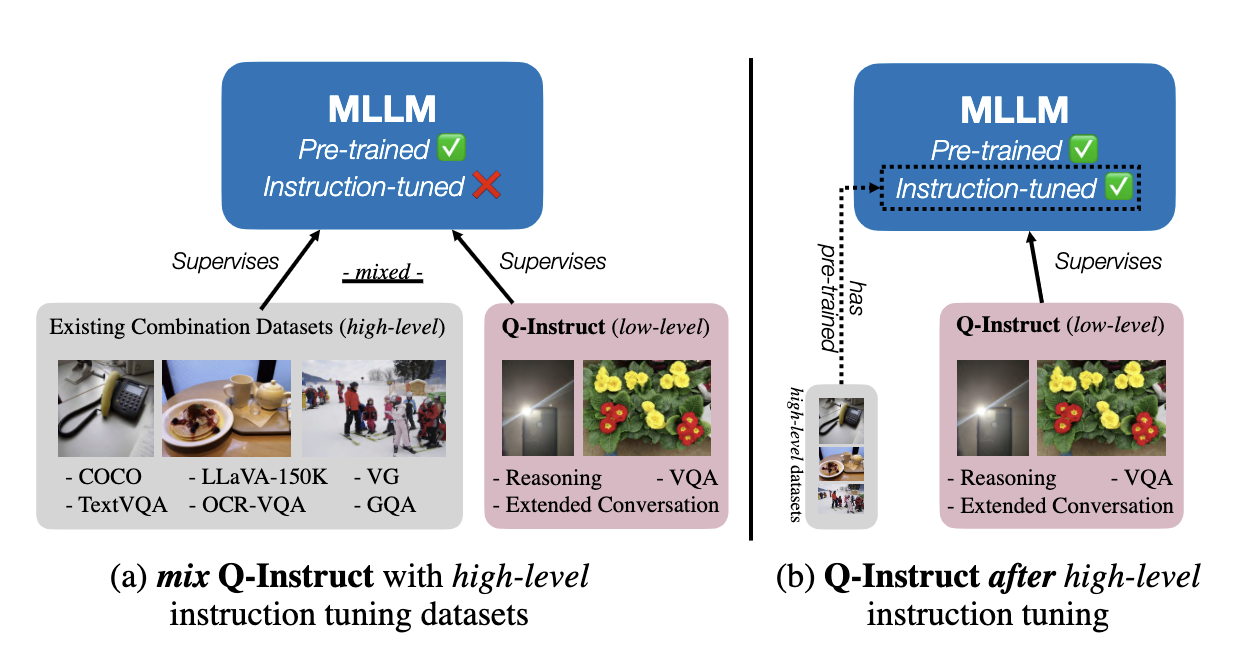
This document provides instruction on how to train with Q-Instruct dataset on LLaVA-v1.5 (7B/13B), under the proposed two strategies (mix and after), shown as follows.
Step 0: Pre-requisites
Install LLaVA under the main repository, with flash attention for more efficient training.
git clone https://github.com/haotian-liu/LLaVA.git
cd LLaVA
pip install -e ".[train]"
pip install flash_attn --no-build-isolation
cd ..
After that, you can conduct low-level visual instruction tuning as follows, under either mix or after strategy.
Step 1: Download Training Datasets
Download Q-Instruct
For the Q-Instruct dataset, download them directly via the following script:
cd LLaVA/playground/data
wget https://huggingface.co/datasets/teowu/Q-Instruct/resolve/main/cleaned_labels.json
wget https://huggingface.co/datasets/teowu/Q-Instruct/resolve/main/q-instruct-images.tar
tar -xf q-instruct-images.tar
rm -f q-instruct-images.tar
cd ../../..
Make sure you have the file structures as follows under LLaVA/playground/data.
├── spaq_koniq
├── livefb_liveitw_aigc
├── cleaned_labels.json
Download Public High-level Instruction Tuning Datasets
If you choose the mix strategy, the high-level datasets also need to be downloaded via the following steps:
- Download the annotation of the final mixture our instruction tuning data llava_v1_5_mix665k.json:
wget -P LLaVA/playground/data https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K/blob/main/llava_v1_5_mix665k.json
- Download the images from constituting datasets:
- COCO: train2017
- GQA: images
- OCR-VQA: download script, we save all files as
.jpg - TextVQA: train_val_images
- VisualGenome: part1, part2
After downloading all of them, organize the high-level data as follows in LLaVA/playground/data,
├── coco
│ └── train2017
├── gqa
│ └── images
├── ocr_vqa
│ └── images
├── textvqa
│ └── train_images
└── vg
├── VG_100K
└── VG_100K_2
- Merge the Q-Instruct labels with labels from high-level datasets.
jq -s 'add' LLaVA/playground/data/cleaned_labels.json LLaVA/playground/data/llava_v1_5_mix665k.json > LLaVA/playground/data/mix_cleaned_labels.json
Step 2: Start Training
Please make sure you have enough computational resources before training.
Strategy (a): Mix with High-level Datasets
- (Pre-requisite) Get Pre-trained Multi-modal Projectors from original LLaVA-v1.5
sh scripts/llava_v1.5/get_mm_projectors.sh
- 13B (requires 8x A100 80G), 21h
sh scripts/llava_v1.5/mix_qinstruct_llava_v1.5_13b.sh
- 7B (requires 8x A100 40G), 18h
sh scripts/llava_v1.5/mix_qinstruct_llava_v1.5_7b.sh
Strategy (b): After High-level Datasets
- 13B (requires 8x A100 80G), 3.5h
sh scripts/llava_v1.5/after_qinstruct_llava_v1.5_13b.sh
- 7B (requires 8x A100 40G), 3h
sh scripts/llava_v1.5/after_qinstruct_llava_v1.5_7b.sh