质衡: 通用基础模型在底层视觉上的基准测试
_Q-Bench中文版,包含中文版【底层视觉问答】和【底层视觉描述】。_质衡 (Q-Bench) 是一个全新的基准,专门为测试中文多模态大模型在低层次机器视觉任务中的性能而设计。此基准集中于三个主要领域:感知(A1),描述(A2)和评估(A3)。这些领域分别对应于多模态大模型在理解和描述视觉信息方面的不同能力。
未来会进行测评的模型:
- [CogVLM] (待发布中文版)
- [MPlug-Owl-Multilingual] (待发布中文版)
数据
A1: 感知(问答)
我们将数据集分成两半:验证集(dev)和测试集(test),划分如下。

同英文版Q-Bench一致,图片发布在 huggingface 仓库的 images.tar 文件中。
验证集和测试集对应的中文标注地址如下:
A2: 描述
描述任务需要的图片被发布在 images.tar 文件中。
A3: 评价
请参考英文指南下载各个公开的图像质量评价数据集。
榜单
A1: 感知(问答)
由于测试的模型同时支持英语,因此我们除了对比模型间的能力外,还对比模型的双语能力差距。总的来说,大部分模型的中文表现始终略逊英文表现。唯一的例外也是中文表现最好的模型是internlm-xcomposer-vl,中文表现和英文表现基本相当。
- 验证集
| 模型 | yes-or-no | what | how | distortion | others | in-context distortion | in-context others | 总分 |
|---|---|---|---|---|---|---|---|---|
| internlm-xcomposer-vl 英文 | 0.6800 | 0.6371 | 0.5780 | 0.5836 | 0.6875 | 0.5855 | 0.7061 | 0.6334 |
| internlm-xcomposer-vl 中文 | 0.6491 | 0.6394 | 0.5821 | 0.5934 | 0.6921 | 0.5592 | 0.7346 | 0.6388 (+0.0054) |
| llava_v1.5 英文 | 0.6909 | 0.6327 | 0.5639 | 0.5525 | 0.6852 | 0.6086 | 0.7306 | 0.6314 |
| llava_v1.5 中文 | 0.6473 | 0.5796 | 0.5659 | 0.5175 | 0.6412 | 0.5954 | 0.7061 | 0.6000 (-0.0314) |
| qwen_vl 英文 | 0.6309 | 0.5819 | 0.5639 | 0.5058 | 0.6273 | 0.5789 | 0.7388 | 0.5940 |
| qwen_vl 中文 | 0.6255 | 0.5774 | 0.5051 | 0.4942 | 0.5972 | 0.5658 | 0.6939 | 0.5712 (-0.0228) |
| visualglm 英文 | 0.6018 | 0.5420 | 0.4625 | 0.5175 | 0.5440 | 0.5362 | 0.5714 | 0.5378 |
| visualglm 中文 | 0.5509 | 0.4867 | 0.4300 | 0.4202 | 0.5139 | 0.4638 | 0.6367 | 0.4916 (-0.0462) |
- 测试集
| 模型 | yes-or-no | what | how | distortion | others | in-context distortion | in-context others | 总分 |
|---|---|---|---|---|---|---|---|---|
| internlm-xcomposer-vl 英文 | 0.6733 | 0.5835 | 0.6235 | 0.5547 | 0.6897 | 0.5582 | 0.7605 | 0.6294 |
| internlm-xcomposer-vl 中文 | 0.6478 | 0.6508 | 0.5556 | 0.5432 | 0.6515 | 0.5993 | 0.7376 | 0.6187 (-0.0107) |
| llava_v1.5 英文 | 0.6734 | 0.6334 | 0.5412 | 0.5278 | 0.6802 | 0.5856 | 0.7338 | 0.6181 |
| llava_v1.5 中文 | 0.6496 | 0.6009 | 0.5556 | 0.5298 | 0.6611 | 0.5788 | 0.6882 | 0.6040 (-0.0141) |
| qwen_vl 英文 | 0.6533 | 0.6074 | 0.5844 | 0.5413 | 0.6635 | 0.5822 | 0.7300 | 0.6167 |
| qwen_vl 中文 | 0.6113 | 0.5944 | 0.5350 | 0.4894 | 0.6253 | 0.5890 | 0.6844 | 0.5813 (-0.0354) |
| visualglm 英文 | 0.6131 | 0.5358 | 0.4403 | 0.4856 | 0.5489 | 0.5548 | 0.5779 | 0.5331 |
| visualglm 中文 | 0.5821 | 0.4512 | 0.4444 | 0.4472 | 0.5155 | 0.4829 | 0.5817 | 0.4970 (-0.0361) |
A2: 描述
由于此项任务中GPT辅助测评具有很强的主观性,中文的描述任务分数和英文的描述任务分数难以直接进行比较。另外,目前在中文GPT辅助下的准确性评价指标的绝对分数还存在一些问题(相对分数的比例基本符合人的感知),因此目前版本的榜单仅供参考。
| Model Name | p_{0, 完整性} | p_{0, 完整性} | p_{2, 完整性} | s_{完整性} | p_{0, 准确性} | p_{0, 准确性} | p_{2, 准确性} | s_{准确性} | p_{0, 相关性} | p_{0, 相关性} | p_{2, 相关性} | s_{相关性} | s_{总分} |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| llava_v1.5 | 4.61% | 52.53% | 42.86% | 1.38/2.00 | 67.95% | 26.84% | 5.20% | 0.37/2.00 | 0.65% | 23.36% | 75.99% | 1.75/2.00 | 3.51/6.00 |
| qwen_vl | 12.79% | 53.05% | 34.16% | 1.21/2.00 | 62.46% | 31.58% | 5.96% | 0.44/2.00 | 15.24% | 34.23% | 50.54% | 1.35/2.00 | 3.00/6.00 |
| visualglm | 6.48% | 52.58% | 40.94% | 1.34/2.00 | 76.80% | 19.76% | 3.44% | 0.27/2.00 | 0.49% | 31.52% | 67.98% | 1.67/2.00 | 3.29/6.00 |
目前有关internlm-xcomposer-vl的中文描述能力正在测试中。
A3: 评价
由于中文语序/语法的原因,类似于英文Q-Bench的质量评价方案暂不适用中文。此外,由于该任务并没有显式的文本输出,我们暂时没有利用中文进行IQA的计划。
以下是英文Q-Bench进行IQA的方案:
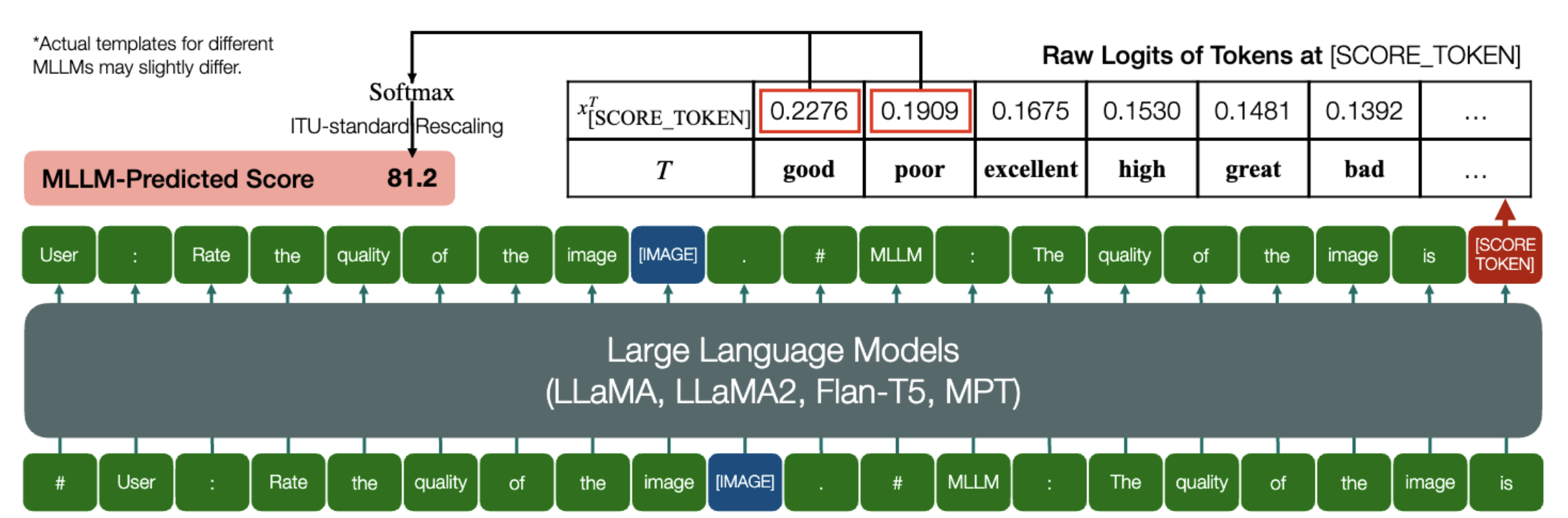
欢迎社区贡献智慧提出针对性的中文IQA设计方案,由我们进行测试~
联系
质衡由新加坡南洋理工大学和中国上海交通大学的研究者们开发。如有任何疑问,您可联系主要作者以获取相关信息:
- Haoning Wu,
haoning001@e.ntu.edu.sg, @teowu - Zicheng Zhang,
zzc1998@sjtu.edu.cn, @zzc-1998 - Erli Zhang,
ezhang005@e.ntu.edu.sg, @ZhangErliCarl
引用
如果需要引用本工作,敬请使用下述 bibtex 文本。
@article{wu2023qbench,
title={Q-Bench: A Benchmark for General-Purpose Foundation Models on Low-level Vision},
author={Wu, Haoning and Zhang, Zicheng and Zhang, Erli and Chen, Chaofeng and Liao, Liang and Wang, Annan and Li, Chunyi and Sun, Wenxiu and Yan, Qiong and Zhai, Guangtao and Lin, Weisi},
year={2023},
}